新年、DeepLearnningの勉強のため、丸っとコピーで勉強する。
勉強チュートリアルは、ちゃまさんの「Xceptionを転移学習させてセーラームーンのキャラを分類する」
そして、せっかくNVIDIAのGTX1650を積んでいるのでCUDAで高速化を図る。
まず、Python11.0で躓き、先人の知恵を借用。
実力があれば直接NVIDIAのものを使うのがよいのでしょうが、2023年1月時点では、金子先生の記事で最新の設定だと思う。
NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.8,NVIDIA cuDNN v8.6 のインストールと動作確認(Windows 上)https://www.kkaneko.jp/tools/win/cuda.html
から、構築したがいろいろあったので備忘録として残す。
python 3.10.9
NVIDIA CUDA ツールキット 11.8,NVIDIA cuDNN v8.6
他インストール
tensorflow: pip install --user tensorflow-gpu
pythorch: pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118
設定確認
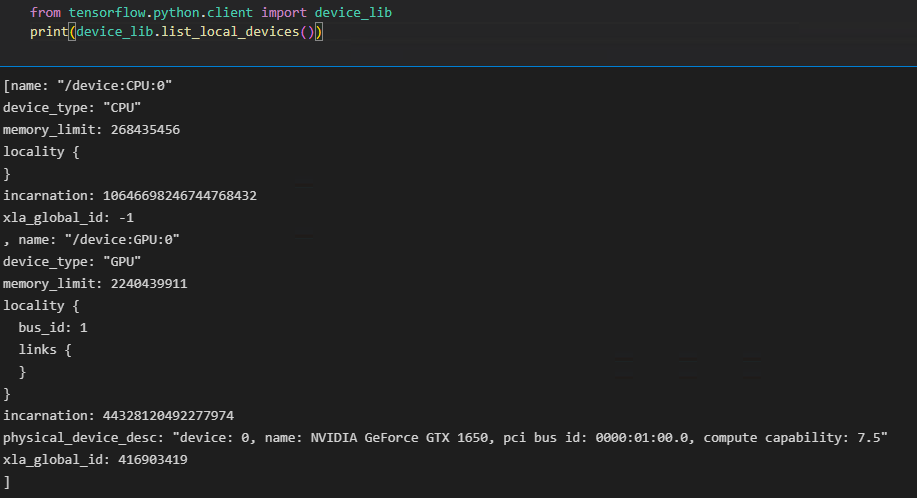
# The package on pypi is called tensorflow-gpu but you just import it with "tensorflow"
import tensorflow as tf このまま使えるらしい。
下記のようにして使えと、情報があったが情報源は不明なのでおまじないとするが、deviceをどう使ったらいいのかわからなかった。
# CUDA 稼働設定
import os
import torch
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
print(f"Using GPU is CUDA:{os.environ['CUDA_VISIBLE_DEVICES']}")
for i in range(torch.cuda.device_count()):
info = torch.cuda.get_device_properties(i)
print(f"CUDA:{i} {info.name}, {info.total_memory / 1024 ** 2}MB")
device = torch.device("cuda:0")
補足1
ちゃまさんの「Xceptionモデル」ではbatch_size=70 だったが、
model.compile(
loss=keras.losses.categorical_crossentropy,
optimizer="adam",
metrics=["accuracy"]
OOM stands for "out of memory". Your GPU is running out of memory, so it can't allocate memory for this tensor. と怒られたので、batch_size=35とする。
補足2
test = np.array(file_list) # THE REQUESTED ARRAY HAS AN INHOMOGENEOUS SHAPE AFTER 1 DIMENSIONS. では、明示的にデータタイプ(string)の指定が必要だった。
test = np.array(file_list, dtype=object) とする。