物忘れが激しいため、『思い出しKaggle初歩用語集』を書いておく
【回帰問題 評価指標】
i) RMSE(二乗平均平方根誤差)
・各要素の誤差(予想値-実測値)の2乗を足したものの平均の平方根
・外れ値の影響が強いので事前に外れ値を外す処理が必要
ii) RMSLE(二乗平均平方根対数誤差)
・RMSEを対数差としたものだが、log0を回避する +1 処理を加える
・対数変換して正規分布になるようなものに適応する
・下振れを回避したいような問題
(売れるのに在庫が不足するようなことを避けたいとき)
【2値分類問題 評価指標】
・ROC曲線とAUC面積 で評価する
理想値結果では :逆L字型で、AUC=1
ランダム結果では:y=xで、AUC=0
1. 前処理での "欠損値" の処理方法
1)解析に影響なしとし、そのまま使う
2)代表値(平均値や中央値=データの偏りがある場合)を使う
3)欠損値であること自体の特徴量を新たに作る
4)ほかのカラムデータとの関連を考慮し、推定した値を用いる
1. 前処理での "One-hot-encoding" 手法
・カテゴリー別にフラグを立てる、横軸がカテゴリー数になる2次元配列になる
・数値であっても相関がないものに対して用いる
(1組,2組,3組のような数値関連のないもの)
・scikit-learn や pandas関数に関数が用意されている
1. 前処理での "正規化" 手法
1)特徴量として扱うデータのスケールをそろえる
2)活性化関数の出力が0から1.0なのでこれに合わせる
2. 解析方法 "LightGBM" モデル
1)特徴量は数値である必要がある
2)欠損値をそのままで使える
3)特徴量のスケーリングが不要
2. 解析方法 "多層パーセプトロン、
ニューラルネットワーク(畳み込み、再帰型)" モデル
出力
=(入力の総和=Σ(重み係数 * 入力信号)+バイアス)* 活性化関数
=(発火の有無)
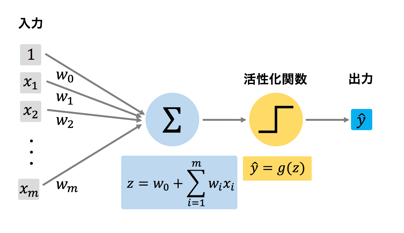
・活性化関数-シグモイド関数
予測の信頼度を確率で出力する活性化関数
・ニュートロンを多層で配置し、入力値から予測値を出力する
1)TensorFlow,Keras,PyTorch,Chainer関数
2)設定項目:
層の数、活性化関数、損失関数(目的関数)、サンプルバッチ数、
学習エポック数
3. 設定項目
1)学習率
勾配降下法における収束のための入力値更新のための勾配係数(0.1~0.01)
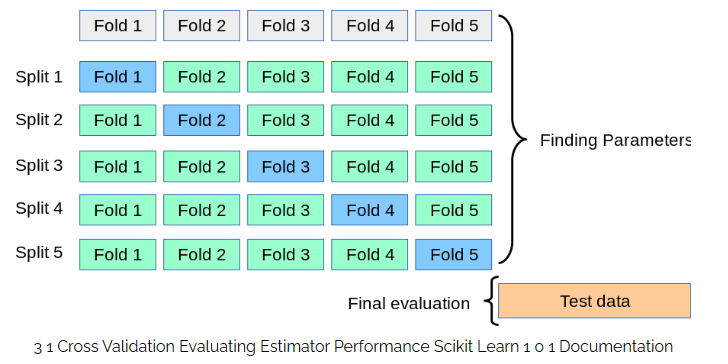
4. 解析-展開方法 "クロスバリデーション"
4. 解析-展開方法 "アンサンブル”
検討したそれぞれのモデルを重みづけした割合に応じて加算したもの
[なぜ、こんな単純式でよいかは不明?]
例)preds = lasso_preds*0.7 + xgb_preds=0.3
solution = pd.Dataset({“id”:test.Id, “SalesPrice”:preds})
5.解析-パラメータチューニング
・ハイパーパラメータ:多層パーセプトロンにおけるチューニング
・自動探索
1)グリッドサーチ(scikit-learn model_selection.GridSearchCV):
すべての組み合わせの総当たり
2)ランダムサーチ(scikit-learn model_selection.RandomizedSearchCV):
ベストを見逃す危険もあり
3)ベイズ最適化:
探索履歴のパラメータとスコアをもとにモデルを作って、パラメータを
探索する
Tips-関数
1)指数関数
微積分しても様式の変化がない関数・・・いわれてみれば、そうだった!
2)ソフトマックス関数
各クラスの総和が1になるため、マルチクラス分類に用いられる
3)尤度関数
結果から、前提条件の数値を変数とするもっともらしさを表す関数
ニューラルネットワークの中間層の出力には正解値がないため、
期待する出力推定値との乖離を測定する
【Tips】
・画像のリサイズ機能:tensorflow の ImageDataGenerator クラス
・メモリ解放:メモリ制限コンペなどでは、不要になったオブジェクトは
del で削除したのち、gc.collect() によるメモリ解放を行う